从零认识 ClaudeCode-01: 基于 QwenCoderPlus 打造一个 BashAgent 笔记
目录
- 1. 项目背景与参考 *Content-[00:00]
- 2. 基础模型调用实现 *Content-[00:55]
- 3. 模型局限性分析与手动执行 *Content-[01:48]
- 4. 复杂任务与 Agentic Loop 概念 *Content-[04:45]
- 5. Agent 流程设计与消息管理 *Content-[07:45]
- 6. 工具定义与系统提示词 *Content-[09:45]
- 7. 代码实现:循环与工具调用 *Content-[11:25]
- 8. 工具结果处理与闭环 *Content-[13:45]
- 9. 最终测试与总结 *Content-[16:00]
- AI 总结
1. 项目背景与参考 *Content-[00:00]
视频开启了一个新系列,旨在从零开始认识并构建类似 Claude Code 的编程助手。
- 市场现状:目前市面上有许多编程工具,如 OpenAI 的 CodeX,Anthropic 的 Claude Code,以及国内的 Kimi、MiniMax 等。
- 差距分析:不同工具在使用体验上存在巨大差距,原因主要有两点:
- 基座模型的能力不同。
- 整个 Code 系统 的设计架构不同。
- 参考项目:本系列代码主要参考了 GitHub 上的开源项目 learn-claude-code。
- 开发者:shanshank Lab。
- 特点:核心依赖只有一个 Anthropic SDK,其余全部用纯 Python 编写。代码简单但系统设计经过深思熟虑。
2. 基础模型调用实现 *Content-[00:55]
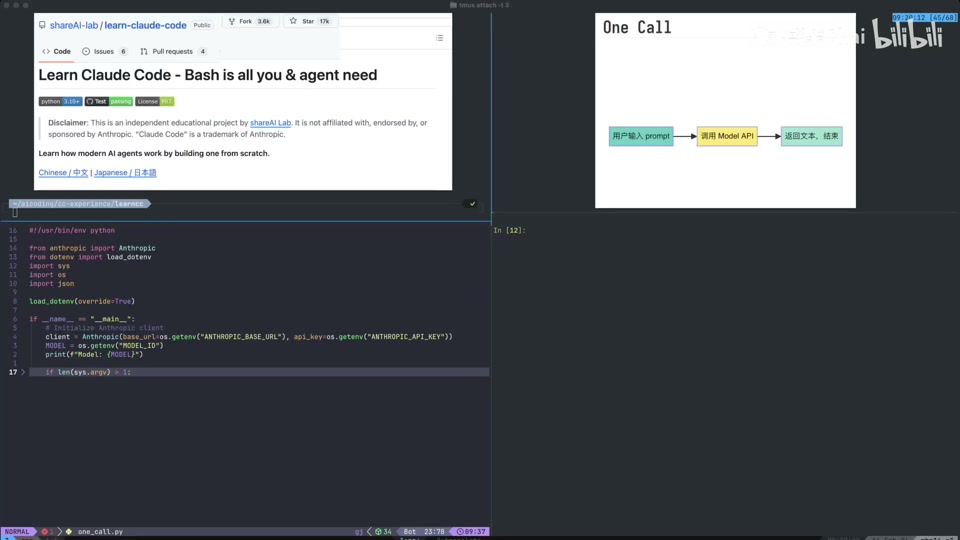
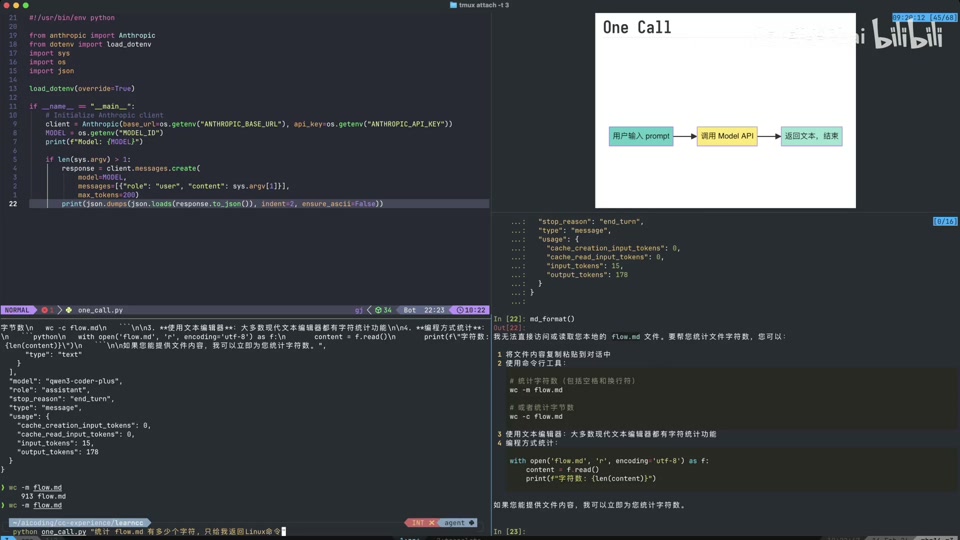
首先回顾最原始的模型调用方式,即“用户输入 Prompt -> 调用 Model API -> 返回文本 -> 结束”。
- 环境配置:需要配置三个关键参数:
BASE_URLAPI_KEYModel Name(模型名称)
- 初始化客户端:使用
BASE_URL和API_KEY初始化 Client。 - 调用接口:使用
client.messages.create函数。- 输入模型名称。
- 组织消息列表(Messages),包含角色(
user)和内容(content)。 - 设置
max_tokens(例如 200)。
- 测试案例:
- 使用国内模型(如 Qwen-Coder-Plus 或 Kimi)进行测试。
- 只需替换
URL和Key即可适配不同模型。 - 简单提问:”1+1 等于几”,模型能正确返回文本结果。
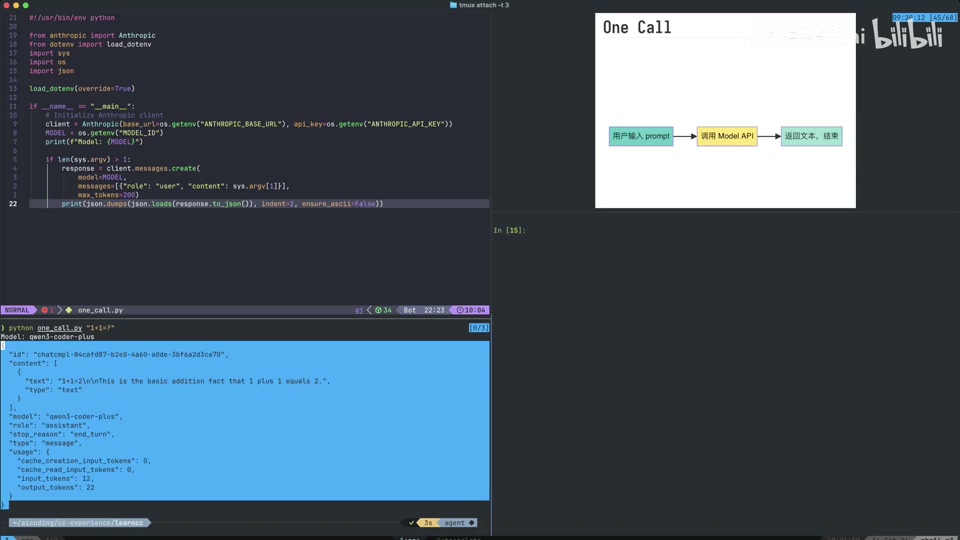
- 响应结构解析:
role:assistant,表示模型返回的消息。stop_reason:end_turn,表示对话轮次结束。content: 一个列表,包含多个块(Block)。type:text,表示返回的是文本消息。text: 具体的文本内容(例如 “1+1 等于 2″)。
3. 模型局限性分析与手动执行 *Content-[01:48]
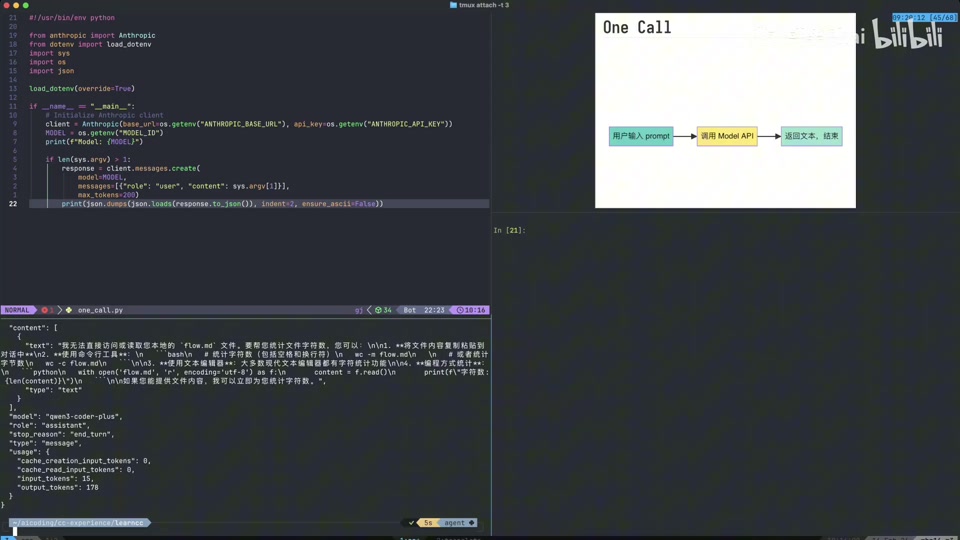
- 局限性测试:让模型统计本地文件
flow.md的字符数。- 模型回复无法直接访问本地文件,但提供了统计办法(如使用
wc命令)。 - 原因:原始调用方式只能返回文本,没有后续动作,模型无法感知本地环境。
- 模型回复无法直接访问本地文件,但提供了统计办法(如使用
- 初步解决方案:
- 通过 Prompt Engineering 强制模型只返回 Linux 命令。
- 测试发现模型能输出
wc -c flow.md。 - 手动执行:用户在终端手动复制粘贴命令执行,得到结果。
- 自动化思路:
- 提取命令:从 Response 的
content字段中提取文本。 - 清洗数据:去除 Markdown 格式(如 “`bash)和前缀说明。
- 执行命令:使用 Python 的
subprocess模块运行提取出的命令。 - 获取输出:读取
stdout得到执行结果(如 1093 个字符)。
- 提取命令:从 Response 的
通过这种方式,给大模型加上了执行本地 Shell 命令的能力,但这仍然是单轮的、手动的流程。
4. 复杂任务与 Agentic Loop 概念 *Content-[04:45]
- 复杂案例:要求模型找到项目中最大的 Python 文件,统计函数数量,并在文件开头添加注释。
- 执行难点:这是一个分步执行的过程。
- 执行
find命令找到文件。 - 执行
grep命令统计函数。 - 执行
sed或其他命令写入文件。
- 关键点:每一步的输入依赖于上一步的输出,模型必须看到结果后才能决定下一步做什么。
- 执行
- 核心概念:Agentic Loop
- 模型在循环中不断地 观察 (Observe)、决策 (Decide)、执行 (Act)。
- 不是一次性给出所有命令,而是交互式地进行。
5. Agent 流程设计与消息管理 *Content-[07:45]
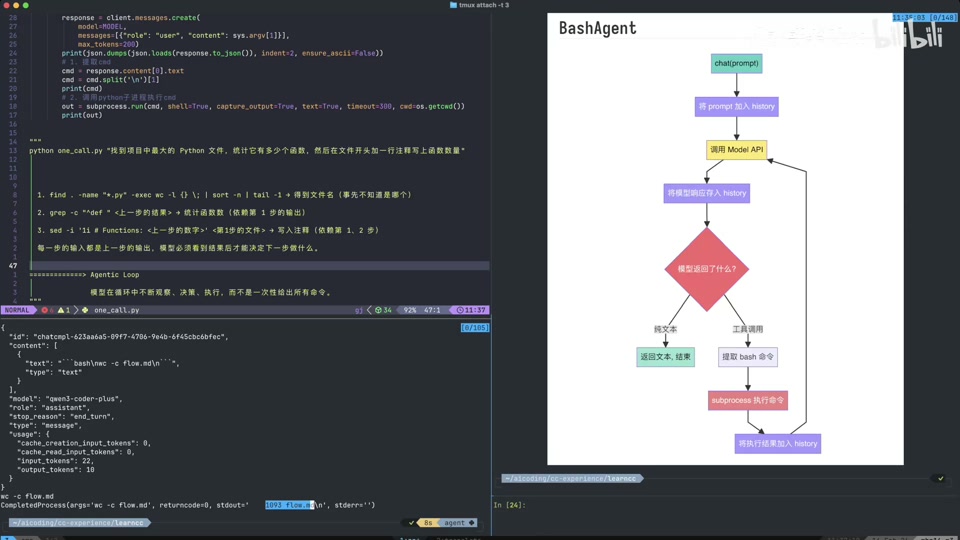
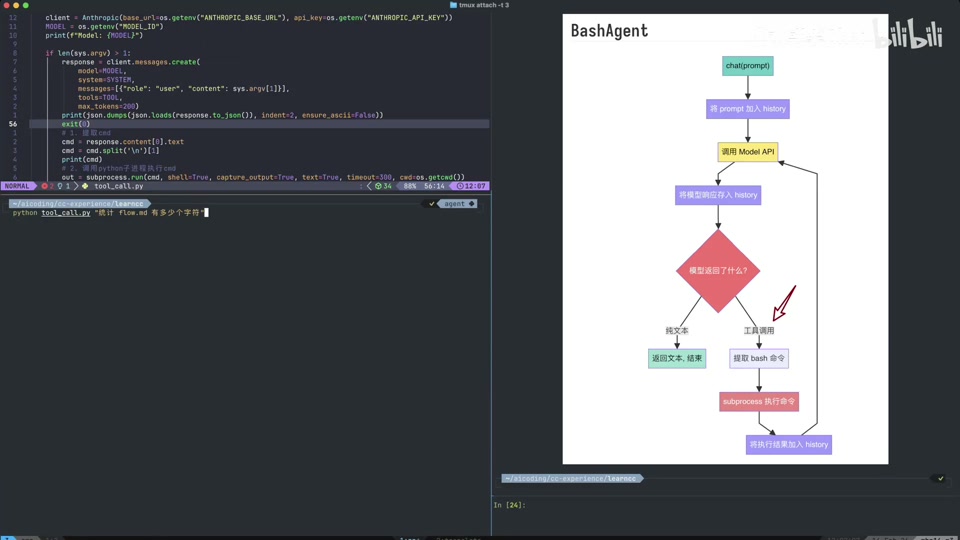
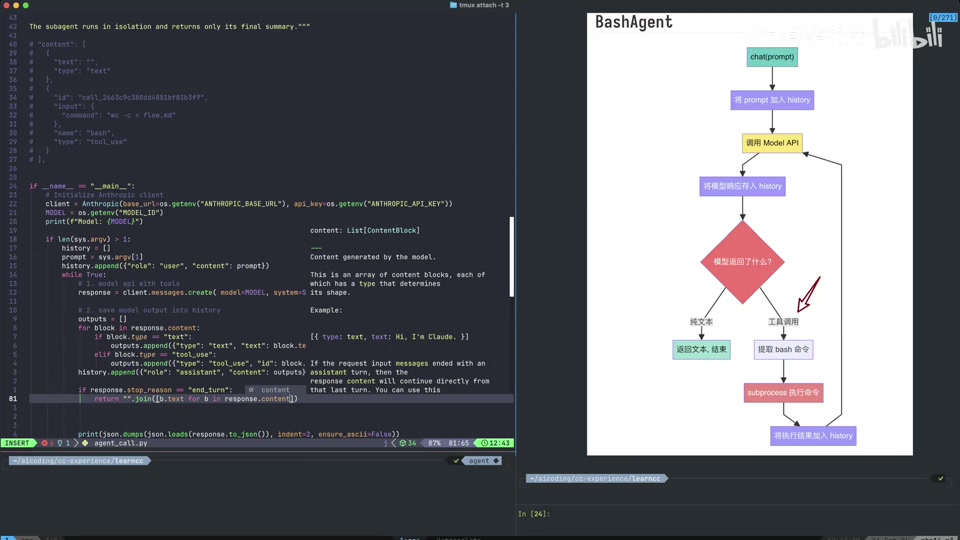
视频展示了加入 Agentic Loop 后的系统流程图。
- 流程演变:
- 原始:Chat Prompt -> Call Model API -> Return Text。
- 进阶:Return Text -> 提取 Bash 命令 -> 子进程执行。
- 完整 Loop:引入消息历史管理 (History) 和工具调用判断。
- 消息管理 (History):
- 每次调用模型时,需将前面所有的消息拼接起来传给模型,保持上下文连贯。
- 第一步将用户的 Prompt 放入
History。
- 判断逻辑:
- 检查模型返回的
stop_reason。 - 如果是
end_turn,则输出最终文本结果,结束循环。 - 如果不是(例如
tool_use),则进入工具调用处理流程。
- 检查模型返回的
- 类型区分:
type: text:普通文本回复。type: tool_use:模型请求调用工具。
6. 工具定义与系统提示词 *Content-[09:45]
为了让模型知道有哪些工具可用,需要在 client.messages.create 参数中定义 tools。
- Tools 规范:是一个列表,每个工具包含三个字段:
name:工具名称(例如bash)。description:工具描述(告诉模型这个工具是干什么的)。input_schema:输入参数的 Schema 定义。type:object。properties: 定义参数(如command,类型为string)。required: 指定必填参数。
- System Prompt:
- 在请求中加入
system参数。 - 告诉模型它是一个 CLI Agent。
- 规定行为准则:使用 Bash 命令解决问题,何时调用子进程,如何返回结果等。
- 在请求中加入
加入 Tools 和 System Prompt 后,再次测试统计字符数:
- 模型返回的
stop_reason变为tool_use。 content列表中出现第二个块,type为tool_use。- 包含
name(bash) 和input(command:wc -c flow.md)。
7. 代码实现:循环与工具调用 *Content-[11:25]
代码实现的核心是一个 while True 循环,用于维持 Agentic Loop。
- 步骤 1:初始化 History
- 将用户 Prompt 作为
user角色加入history列表。
- 将用户 Prompt 作为
- 步骤 2:调用模型
- 传入
messages=history和tools配置。
- 传入
- 步骤 3:保存模型输出
- 将模型的
output(Assistant 消息) 追加到history中。
- 将模型的
- 步骤 4:判断结束条件
- 检查
response.stop_reason。 - 若为
end_turn,拼接所有文本块内容,打印结果并break退出循环。
- 检查
- 步骤 5:处理工具调用
- 若未结束,遍历
response.content。 - 找到
type为tool_use的块。 - 提取
name和input(command)。 - 使用
subprocess.run执行命令,捕获stdout。
- 若未结束,遍历
8. 工具结果处理与闭环 *Content-[13:45]
为了让循环继续,必须将工具执行的结果反馈给模型。
- 构建 Tool Result:
- 创建一个新的消息块,角色为
user(理解为工具执行结果由“外部”返回给用户/系统)。 type:tool_result。tool_use_id: 对应之前工具调用的id。content: 子进程执行的输出结果(stdout)。
- 创建一个新的消息块,角色为
- 更新 History:
- 将这个
tool_result消息块追加到history列表中。
- 将这个
- 循环继续:
while循环回到步骤 2,再次调用模型。- 模型看到上一步的命令执行结果后,决定是继续调用工具还是输出最终结论。
代码逻辑整理:
history.append(user_prompt)while True:response = client.messages.create(..., messages=history, tools=tools)history.append(response)if stop_reason == end_turn: print text; breakfor block in response.content:if type == tool_use:cmd = block.input.commandoutput = subprocess.run(cmd)result_block = {type: tool_result, content: output}history.append(result_block)
9. 最终测试与总结 *Content-[16:00]
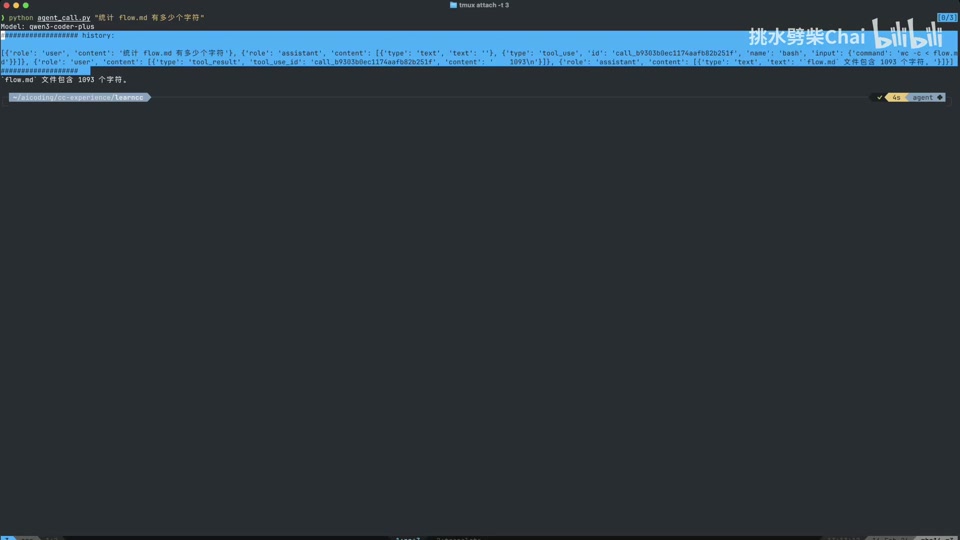
完成代码封装后,进行最终测试。
- 测试案例 1:统计
flow.md字符数。- 过程:模型调用 bash 工具 -> 执行
wc -c-> 返回结果 -> 模型总结输出 “1093 个字符”。 - 日志显示完整的交互历史:User Prompt -> Assistant (Tool Use) -> User (Tool Result) -> Assistant (Text)。
- 过程:模型调用 bash 工具 -> 执行
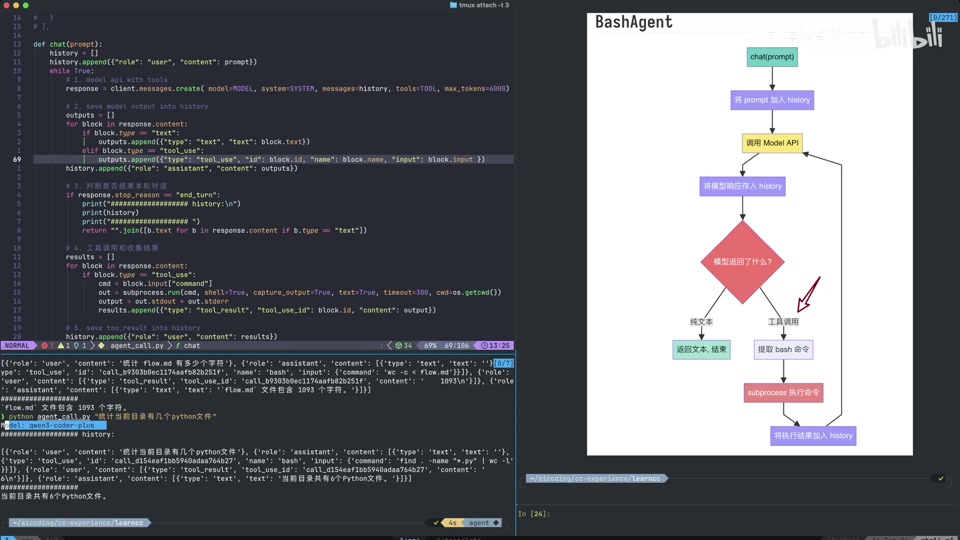
- 测试案例 2:统计当前目录下 Python 文件数量。
- 模型自动调用
find . -name "*.py" | wc -l。 - 返回结果 “6”。
- 模型总结 “当前目录有 6 个 Python 文件”。
- 模型自动调用
- 当前状态:
- 基于 Qwen-Coder-Plus 实现了一个简单的 Bash Agent。
- 当前工具只有一个
bash。
- 未来计划:
- 添加更多工具,如读取文件 (
read_file)、编辑文件 (edit_file) 等,使 Agent 能力更强大。
- 添加更多工具,如读取文件 (
AI 总结
本视频详细演示了如何从零开始构建一个基于 Agentic Loop 的 Bash Agent。内容从最基础的 Model API 调用入手,分析了纯文本交互的局限性,进而引出通过 Tools 和 System Prompt 赋予模型执行本地命令的能力。
核心要点包括:
- 架构设计:采用 Observe-Decide-Act 的循环模式,通过维护 Message History 保持上下文。
- 工具定义:遵循标准 Schema 定义
bash工具,使模型能够结构化地输出命令。 - 闭环实现:利用
subprocess执行命令,并将stdout封装为tool_result反馈给模型,实现多轮自主交互。 - 实战效果:成功实现了文件统计、搜索等自动化任务,验证了 Learn-Claude-Code 设计思路的可行性。
这是一个理解现代 Coding Agent 工作原理的极佳入门实践。